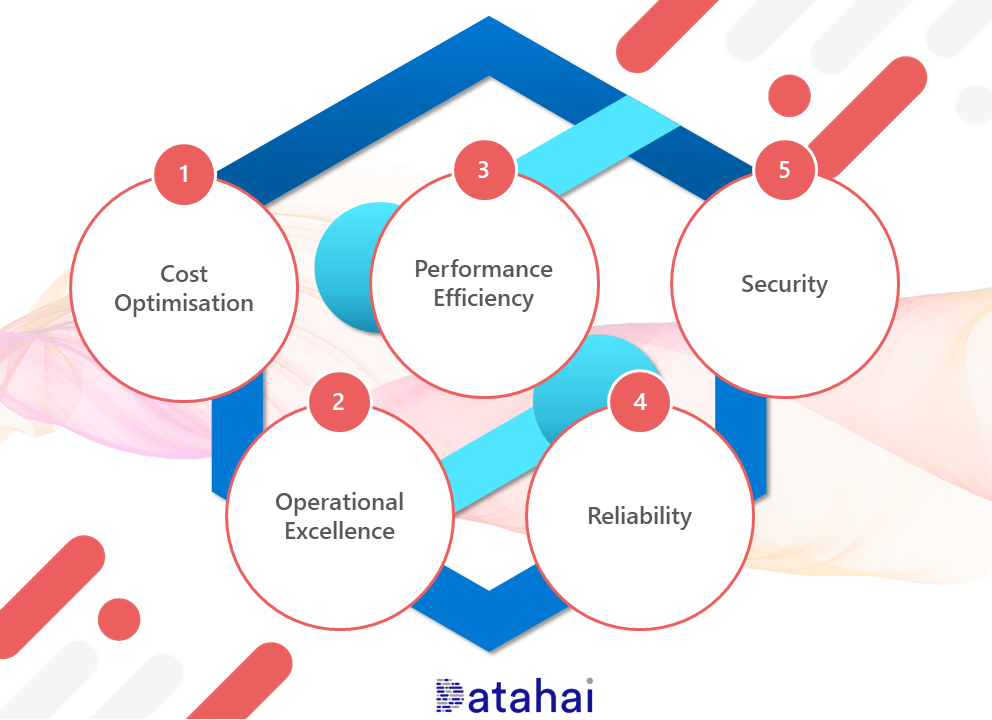
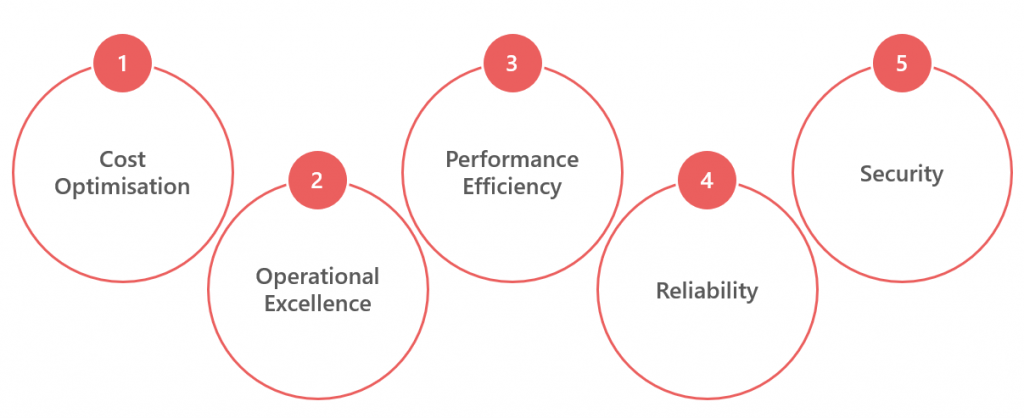
The Microsoft Azure Well-Architected Framework is a set of 5 pillars which can be used to help an organisation improve the quality of their Azure workloads and infrastructure. The principles within these 5 pillars can help guide a person and/or organisation to deploy a safe, performant, and stable Azure Synapse Analytics environment. This framework is available within the Microsoft Azure Architecture Centre which also includes reference architectures to suit a variety of scenarios.
In this blog post we’ll be taking a high-level look at features and services which can be used with Azure Synapse Analytics Dedicated SQL Pools and Serverless SQL Pools to align with the 5 well-architected framework pillars. In future blog posts we will expand the original content for Dedicated SQL Pools & Serverless SQL Pools plus also bring in Spark Pools, Pipelines, and Power BI (integrated with Synapse) into this process. We’ll also look at how we can use the Well-Architected templates available to document the process.
This blog originated from a Data Toboggan session, the recording is available here.
Before we look at the 5 pillars, let’s turn each into a question that could help guide us when deploying/looking to deploy Azure Synapse Analytics.
- Cost Optimisation: “How much does it cost?”
- Operational Excellence: “How do we deploy and monitor it?”
- Performance Efficiency: “Is it fast? Really fast?”
- Reliability: “Will it be available all day every day?”
- Security: “Will unauthorised people be able to access our data?!”
Cost Optimisation
With Cost Optimisation we are looking at managing costs to maximize the value delivered. We should understand the pricing structure and assess workload usage to optimise service usage. This could mean the difference between a CTO/CIO rubber-stamping the use of/continued use of Azure Synapse Analytics. We will not explicitly state any pricing as this differs between regions, this is available on the pricing page here. Please note there are 4 tabs on the pricing page for Data Integration, Data Exploration & Data Warehousing, Big Data Analytics with Apache Spark, and Dedicated SQL Pool.
Dedicated SQL Pools
- Assign compute using DWUs from DWU100 (60GB) to 30000 (18TB) to suit workload. Potentially use a higher DWU to load data then lower the DWU to query data during the day. By understanding daily workload patterns, the DWUs can be set at an appropriate level at certain periods during the day.
- By using services such as Azure Automation, we can scale up and scale down, and also pause to reduce costs.
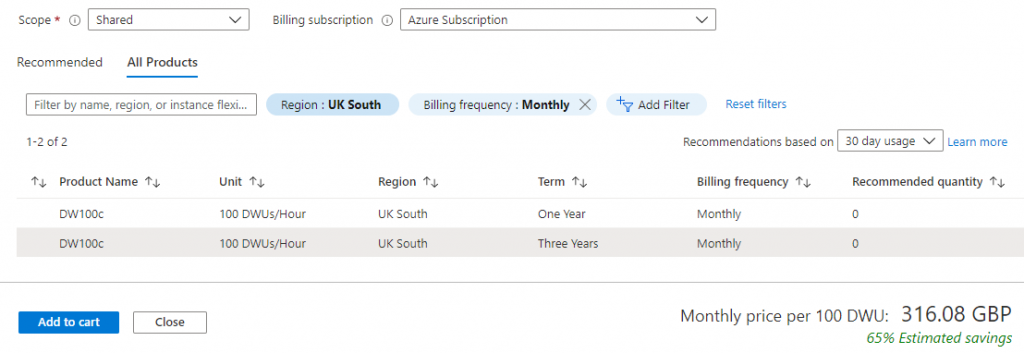
- Azure Reservations can be used to pre-purchase DWUs for 1 & 3 year reserve pricing, this can reduce costs by up to 65%. Reserved pricing can be paid monthly to spread the cost. This works on a “use it or lose it” basis in that if you were to pre-purchase DWU400 (4 x DWU100) and only ever used DWU200 per hour then you would lose the benefit. However, you are able to use the pre-purchased DWUs across environments.
- Storage costs are associated with
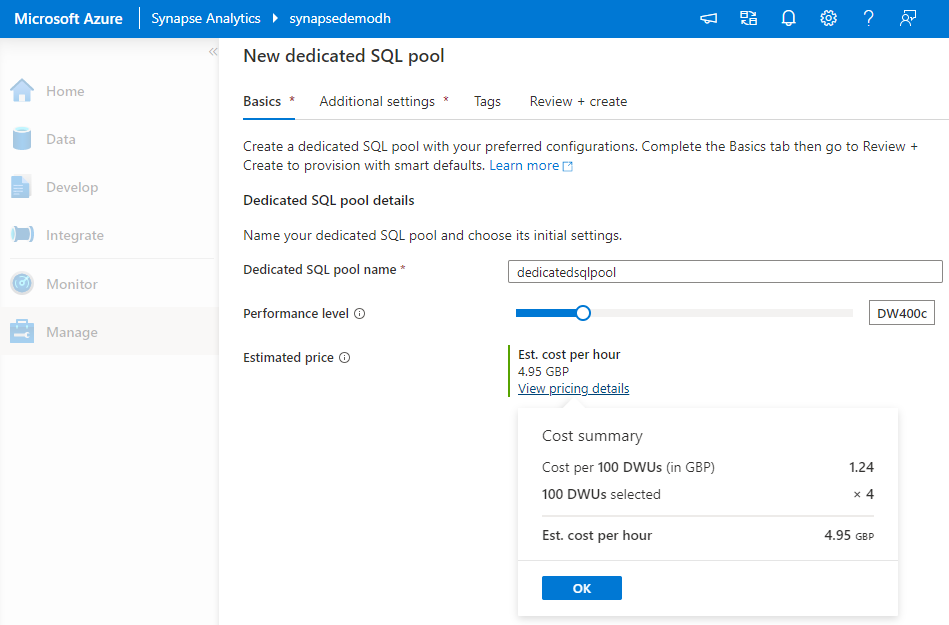
Creating a new Dedicated SQL Pool and setting the initial DWU size. This can be changed at any point after initial creation:
Pre-purchasing DWUs over a 3 year period reduces the cost:
Serverless SQL Pools
- The cost is based on Data Processed rather than processing power or length of time processing queries. This cost includes both Reading data from and Writing data to external storage (Azure Storage, Data Lake Gen1/2, Cosmos DB).
- Microsoft’s Best practice is to optimise data types by using the smallest data type possible and where possible use the Parquet file format to reduce overall data processed.
- You will need to understand your workload patterns to calculate (roughly) daily/weekly/monthly costs. E.G if your workload queries total 1.5TB per day, monthly costs will be £150.
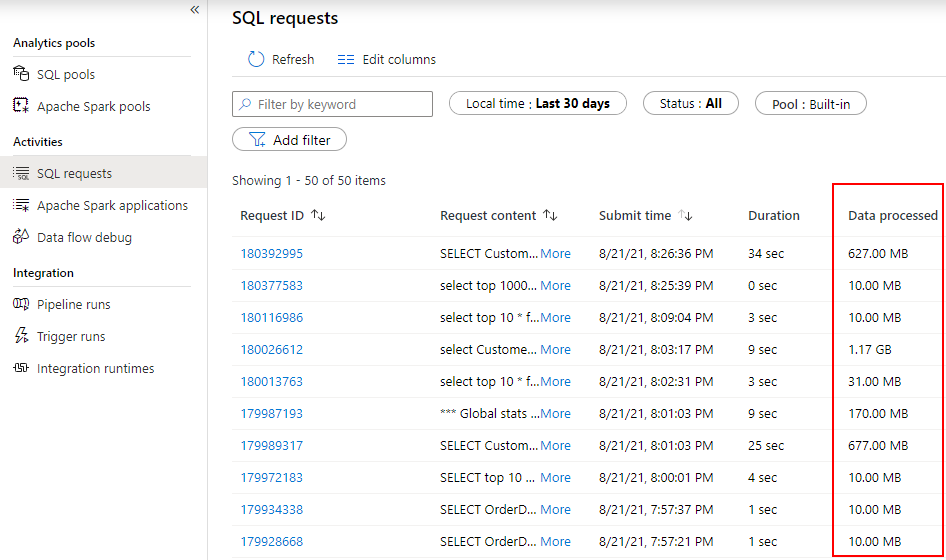
- The Synapse Studio environment includes a Monitoring tab and the Data Processed totals can be see in the SQL Requests tab. This information is also included in the sys.dm_external_data_processed system view within the in-built Serverless SQL Pools engine.
Operational Excellence
With Operational Excellence we are looking at how to deploy and monitor our Synapse Analytics environment and code.
Dedicated SQL Pools
- Database projects are supported and can be created using SSDT in Visual Studio and Azure Data Studio. This ensures we have a development environment which can be connected to source control and enable projects to be built.
- A full CI/CD (Continuous Integration/Continuous Deployment) process can be created using Azure DevOps build and release pipelines to deploy code changes.
- To monitor the activity we can enable logging using Azure Log Analytics.
- Use Azure Monitor to surface alerts and metrics to monitor DWU usage, Cache usage, RAM utilisation, and CPU usage.
- We can use Azure SQL Auditing to understand database activity.
Serverless SQL Pools
- There is currently no SSDT support, however SQL Scripts to create objects can be source controlled using Synapse Studio Git integration.
- There are System Views to track Data Processed volumes by Day, Week, and Month. If limits have been set, monitoring data processed usage is vital.
- Azure Monitor can also surface metrics to monitor data processed volumes, plus login attempts, and ended SQL requests
Performance Efficiency
When looking at Performance Efficiency we are looking at how the system copes with changes to the incoming workload and the ability of that system to adapt to changes in load.
Dedicated SQL Pools
- As there is currently no online auto-scaling with regards to DWUs, resizing compute is an offline process. This can take anywhere from a few seconds to a few minutes and during this time, the Dedicated SQL Pool is unavailable.
- The Workload Classification, Importance, and Isolation feature allows certain workload sizes to be allocated the required resources. This means that certain workload types such as ETL/ELT operations and report queries can be assigned different levels of DWU resources and importance. E.G a report request could be given less importance and resources than an ELT operation, ensuring that the ELT operation completes.

Serverless SQL Pools
- With the Polaris engine there is no ability to set or control any workload settings or classification as the service will scale and allocate resources accordingly during live workloads execution.
- The Polaris engine does not have any settings to scale out/up in terms of compute performance. The engine assesses the required resources to meet the needs of the query and allocates accordingly.
Reliability
With Reliability we are looking at the ability of the system to recover from failures and continue to function.
Dedicated SQL Pools
- When the Dedicated SQL Pool is running, Automatic Restore Points are created periodically during the day and are available for 7 days. You can also create User-Defined Restore Points if you regularly scale/pause the service (limited to 7 Days retention).
- You can enable/disable Geo-Backup which will backup to a paired region, E.G. UK South and UK West.
Serverless SQL Pools
- Automatic Fault tolerance in Polaris engine with an automated query restart process. “Tasks” will be restarted automatically in the event of a failure and this is a seamless process to the user/query executor.
Security
With all the 4 pillars above, whilst they are important, Security is by far the most important. We are now looking at protecting applications and data from threats and unauthorised access. There are Authentication (accessing the service itself) and Authorisation (who can do what once authenticated) features.
Dedicated SQL Pools
- By enabling Firewall rules and using Private Endpoints, we can lock-down Synapse Analytics to only allow access to authenticated people and services.
- Use Azure Active Directory Groups and Users, and SQL Logins to secure database objects and data to ensure only specific people/groups have access to specific data.
- Enable Transparent Data Encryption (TDE) to encrypt data at rest.
- We can enable Azure Defender with periodic Vulnerability Assessment scans to determine current security state.
Serverless SQL Pools
- As with Dedicated SQL Pools we can use Azure Active Directory Groups and Users, and SQL Logins to secure database objects such as Views and External Tables.
- Access to the data itself is based on Azure Storage permissions being allocated to the AAD Group/User, using time-based SAS credentials, and also using the Managed Identity of the Synapse service itself. With Cosmos DB we are authenticating using the database key.
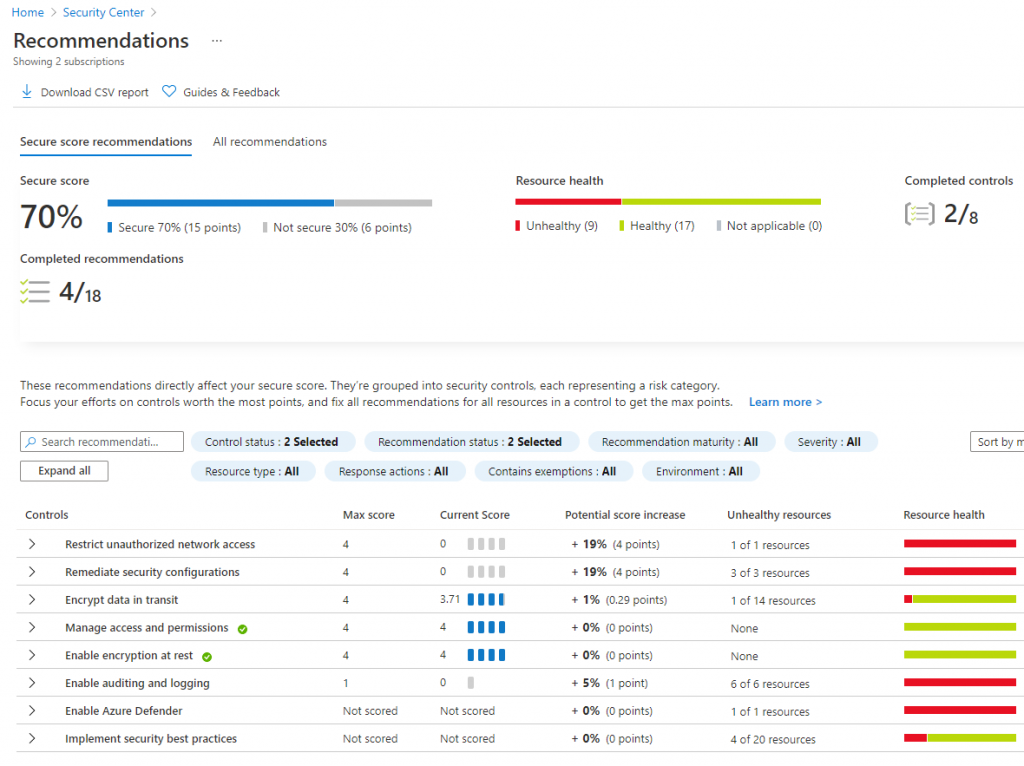
Azure Advisor & Azure Score
We can use Azure Advisor to see what the current score is in terms of recommendations to ensure the environment is as secure as possible.
References
Pricing
- https://azure.microsoft.com/en-us/pricing/details/synapse-analytics/#pricing
- https://docs.microsoft.com/en-us/azure/synapse-analytics/plan-manage-costs
- https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/best-practices-serverless-sql-pool
Operational Excellence
- https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-query-visual-studio
- https://docs.microsoft.com/en-us/azure/azure-monitor/logs/log-analytics-overview
- https://docs.microsoft.com/en-us/azure/azure-sql/database/auditing-overview
Performance Efficiency
- https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-workload-management
- https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-workload-classification
- https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-workload-importance
- https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-workload-isolation
- http://www.vldb.org/pvldb/vol13/p3204-saborit.pdf
Reliability
- https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-restore-points
- https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-restore-active-paused-dw
Security
- https://docs.microsoft.com/en-us/azure/synapse-analytics/security/synapse-workspace-ip-firewall
- https://docs.microsoft.com/en-us/azure/private-link/private-endpoint-overview
- https://docs.microsoft.com/en-us/azure/azure-sql/database/azure-defender-for-sql
- https://docs.microsoft.com/en-us/azure/storage/blobs/security-recommendations
Azure Advisor
- https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-concept-recommendations
- https://docs.microsoft.com/en-us/azure/advisor/advisor-overview